Expression Templates Library (ETL) 1.1
It took me longer than I thought, but I'm glad to announce the release of the version 1.1 of my Expression Templates Library (ETL) project. This is a major new release with many improvements and new features. It's been almost one month since the last, and first, release (1.0) was released. I should have done some minor releases in the mean time, but at least now the library is in a good shape for major version.
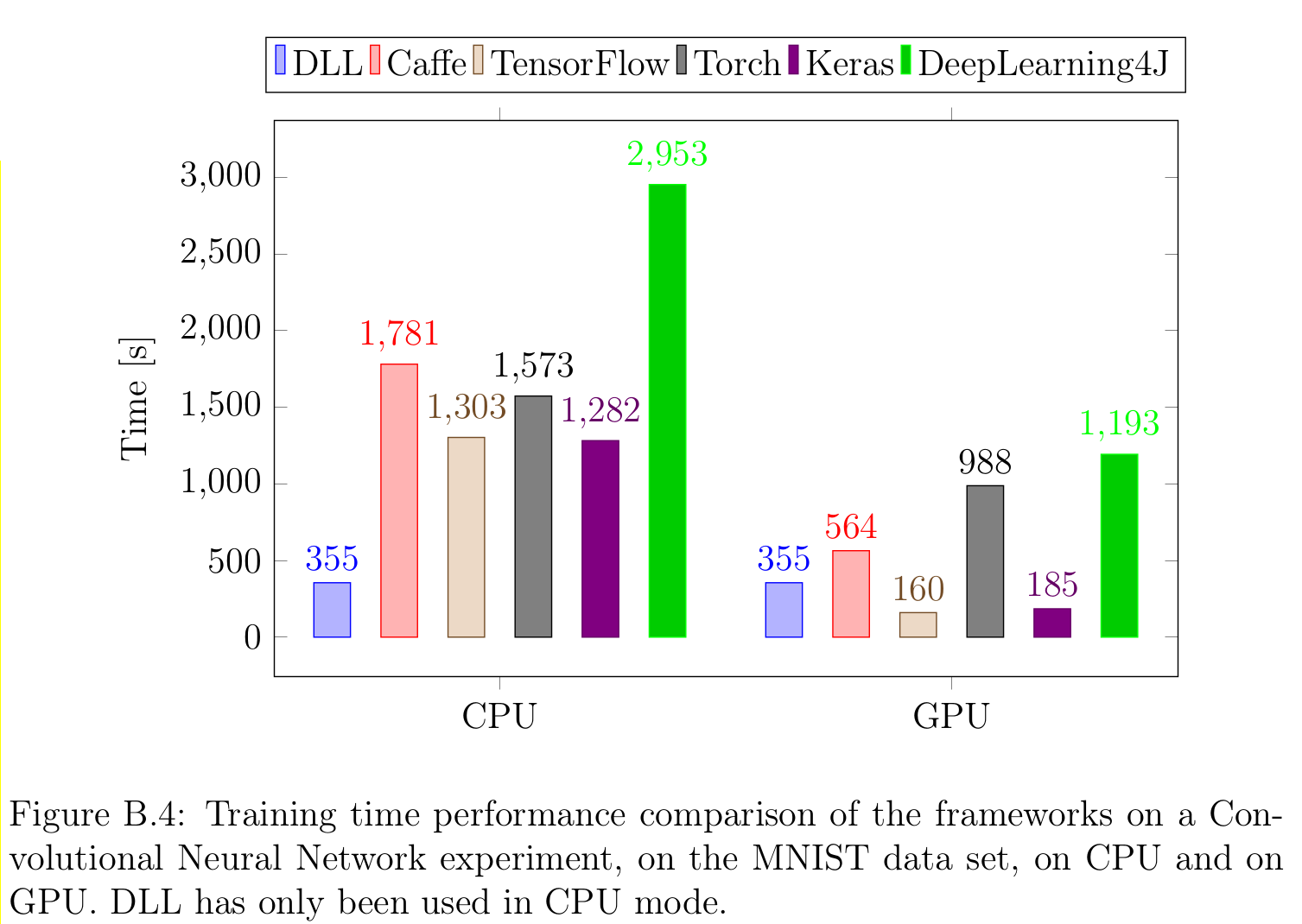
It may be interesting to note that my machine learning framework (DLL), based on the ETL library, has shown to be faster than all the tested popular frameworks (Tensorflow, Keras, Caffee, Torch, DeepLearning4J) for training various neural networks on CPU. I'll post more details on another post on the coming weeks, but that shows that special attention to performance has been done in this library and that it is well adapted to machine learning.
For those of you that don't follow my blog, ETL is a library providing Expression Templates for computations on matrix and vector. For instance, if you have three matrices A, B and C you could write C++ code like this:
Or given vectors b, v, h and a matrix W, you could write code like this:
The goal of such library is two-fold. First, this makes the expression more readable and as close to math as possible. And then, it allows the library to compute the expressions as fast as possible. In the first case, the framework will compute the sum using a vectorized algorithm and then compute the overall expression using yet again vectorized code. The expression can also be computed in parallel if the matrices are big enough. In the second case, the vector-matrix multiplication will be computed first using either hand-code optimized vectorized or a BLAS routine (depending on configuration options). Then, all the expression will be executed using vectorized code.
Features
Many new features have been integrated into the library.
The support for machine learning operations has been improved. There are now specific helpers for machine learning in the etl::ml namespace which have names that are standard to machine learning. A real transposed convolution has been implemented with support for padding and stride. Batched outer product and batched bias averaging are also now supported. The activation function support has also been improved and the derivatives have been reviewed. The pooling operators have also been improved with stride and padding support. Unrelated to machine learning, 2D and 3D pooling can also be done in higher dimensional matrix now.
New functions are also available for matrices and vectors. The support for square root has been improved with cubic root and inverse root. Support has also been added for floor and ceil. Moreover, comparison operators are now available as well as global functions such as approx_equals.
New reductions have also been added with support for absolute sum and mean (asum/asum) and for min_index and max_index, which returns the index of the minimum element, respectively the maximum. Finally, argmax can now be used to get the max index in each sub dimensions of a matrix. argmax on a vector is equivalent to max_index.
Support for shuffling has also been added. By default, shuffling a vector means shuffling all elements and shuffling a matrix means shuffling by shuffling the sub matrices (only the first dimension is shuffled), but shuffling a matrix as a vector is also possible. Shuffle of two vectors or two matrices in parallel, is also possible. In that case, the same permutation is applied to both containers. As a side note, all operations using random generation are also available with an addition parameter for the random generator, which can help to improve reproducibility or simply tune the random generator.
I've also included support for adapters matrices. There are adapters for hermitian matrices, symmetric matrices and lower and upper triangular matrices. For now, the framework does not take advantage of this information, this will be done later, but the framework guarantee the different constrain on the content.
There are also a few new more minor features. Maybe not so minor, matrices can now be sliced into sub matrices. With that a matrix can be divided into several sub matrices and modifying the sub matrices will modify the source matrix. The sub matrices are available in 2D, 3D and 4D for now. There are also some other ways of slicing matrix and vectors. It is possible to obtain a slice of its memory or obtain a slice of its first dimension. Another new feature is that it is now possible compute the cross product of vectors now. Matrices can be decomposed into their Q/R decomposition rather than only their PALU decomposition. Special support has been integrated for matrix and vectors of booleans. In that case, they support logical operators such as and, not and or.
Performance
I've always considered the performance of this library to be a feature itself. I consider the library to be quite fast, especially its convolution support, even though there is still room for improvement. Therefore, many improvements have been made to the performance of the library since the last release. As said before, this library was used in a machine learning framework which then proved faster than most popular neural network frameworks on CPU. I'll present here the most important new improvements to performance, in no real particular order, every bit being important in my opinion.
First, several operations have been optimized to be faster.
Multiplication of matrices or matrices and vectors are now much faster if one of the matrix is transposed. Instead of performing the slow transposition, different kernels are used in order to maximize performance without doing any transposition, although sometimes transposition is performed when it is faster. This leads to very significant improvements, up to 10 times faster in the best case. This is performed for vectorized kernels and also for BLAS and CUBLAS calls. These new kernels are also directly used when matrices of different storage order are used. For instance, multiplying a column major matrix with a row major matrix and storing the result in a column major matrix is now much more efficient than before. Moreover, the performance of the transpose operation itself is also much faster than before.
A lot of machine learning operations have also been highly optimized. All the pooling and upsample operators are now parallelized and the most used kernel (2x2 pooling) is now more optimized. 4D convolution kernels (for machine learning) have been greatly improved. There are now very specialized vectorized kernels for classic kernel configurations (for instance 3x3 or 5x5) and the selection of implementations is now smarter than before. The support of padding is now much better than before for small amount of padding. Moreover, for small kernels the full convolution can now be evaluated using the valid convolution kernels directly with some padding, for much faster overall performance. The exponential operation is now vectorized which allows operations such as sigmoid or softmax to be much faster.
Matrices and vector are automatically using aligned memory. This means that vectorized code can use aligned operations, which may be slightly faster. Moreover, matrices and vectors are now padded to a multiple of the vector size. This allows to remove the final non-vectorized remainder loop from the vectorized code. This is only done for the end of matrices, when they are accessed in flat way. Contrary to some frameworks, inner dimensions of the matrix are not padded. Finally, accesses to 3D and 4D matrices is now much faster than before.
Then, the parallelization feature of ETL has been completely reworked. Before, there was a thread pool for each algorithm that was parallelized. Now, there is a global thread engine with one thread pool. Since parallelization is not nested in ETL, this improves performance slightly by greatly diminishing the number of threads that are created throughout an application. Another big difference in parallel dispatching is that now it can detect good split based on alignment so that each split are aligned. This then allows the vectorization process to use aligned stores and loads instead of unaligned ones which may be faster on some processors.
Vectorization has also been greatly improved in ETL. Integer operations are now automatically vectorized on processors that support this. Before, only floating points operations were vectorized. The automatic vectorizer now is able to use non-temporal stores for very large operations. A non-temporal store bypasses the cache, thus gaining some time. Since very large matrices do not fit in cache anyway and the cache would end up being overwritten anyway, this is a net gain. Moreover, the alignment detection in the automatic vectorizer has also been improved. Support for Fused-Multiply-Add (FMA) operations has also been integrated in the algorithms that can make use of it (multiplications and convolutions). The matrix-matrix multiplications and vector-matrix multiplications now have highly optimized vectorized kernels. They also have versions for column-major matrices now. I plan to reintegrate a version of the GEMM based on BLIS in the future but with more optimizations and support for all precisions and integers, For my version is still slower than the simple vectorized version. The sum and the dot product operations now also have specialized vectorized implementations. The min and max operations are now automatically-vectorized. Several others algorithms have also their own vectorized implementations.
Last, but not least, the GPU support has also been almost completely reworked. Now, several operations can be chained without any copies between GPU and CPU. Several new operations have also been added with support to GPU (convolutions, pooling, sigmoid, ReLU, ...). Moreover, to complement operations that are not available in any of the supported NVIDIA libraries, I've created a simple library that can be used to add a few more GPU operations. Nevertheless a lot of operations are still missing and only algorithms are available not expressions (such as c = a + b * 1.0) that are entirely computed on CPU. I have plans to improve that further, probably for version 1.2. The different contexts necessary for NVIDIA library can now be cached (using an option from ETL), leading to much faster code. Only the main handle can be cached so far, I plan to try to cache all the descriptors, but I don't know yet when that will be ready. Finally, an option is also available to reuse GPU memory instead of directly releasing it to CUDA. This is using a custom memory pool and can save some time. Since this needs to be cleaned (by a call to etl::exit() or using ETL_PROLOGUE), this is only activated on demand.
Other changes
There also have been a lot of refactorings in the code of the library. A lot of expressions now have less overhead and are specialized for performance. Moreover, temporary expressions have been totally reworked to be more simple and maintainable and easier to optimize in the future. It's also probably easier to add new expressions to the framework now, although that could be even more simple. There are also less duplicated code now in the different expressions. Especially, now there are now more SSE and AVX variants in the code. All the optimized algorithms are now using the vectorization system of the library.
I also tried my best to reduce the compilation time, based on the unit tests. This is still not great but better than before. For user code, the next version should be much faster to compile since I plan to disable forced selection of implementations by default and only enable it on demand.
Finally, there also was quite a few bug fixes. Most of them have been found by the use of the library in the Deep Learning Library (DLL) project. Some were very small edge cases. For instance, the transposition algorithm was not working on GPU on rectangular column major matrices. There also was a slight bug in the Q/R decomposition and in the pooling of 4D matrices.
What's next ?
Next time, I may do some minor release, but I don't yet have a complete plan. For the next major release (1.2 probably), here is what is planned:
Review the system for selection of algorithms to reduce compilation time
Review the GPU system to allow more complete support for standard operators
Switch to C++17: there are many improvements that could be done to the code with C++17 features
Add support for convolution on mixed types (float/double)
More tests for sparse matrix
More algorithms support for sparse matrix
Reduce the compilation time of the library in general
Reduce the compilation and execution time of the unit tests
These are pretty big changes, especially the first two, so maybe it'll be split into several releases. It will really depend on the time I have. As for C++17, I really want to try it and I have a lot of points that could profit from the switch, but that will means setting GCC 7.1 and Clang 3.9 as minimum requirement, which may not be reasonable for every user.
Download ETL
You can download ETL on Github. If you only interested in the 1.1 version, you can look at the Releases pages or clone the tag 1.1. There are several branches:
master Is the eternal development branch, may not always be stable
stable Is a branch always pointing to the last tag, no development here
For the future release, there always will tags pointing to the corresponding commits. I'm not following the git flow way, I'd rather try to have a more linear history with one eternal development branch, rather than an useless develop branch or a load of other branches for releases.
The documentation is a bit sparse. There are a few examples and the Wiki, but there still is work to be done. If you have questions on how to use or configure the library, please don't hesitate.
Don't hesitate to comment this post if you have any comment on this library or any question. You can also open an Issue on Github if you have a problem using this library or propose a Pull Request if you have any contribution you'd like to make to the library.
Hope this may be useful to some of you :)