DLL: Blazing Fast Neural Network Library
A few weeks ago, I talked about all the new features of my Deep Learning Library (DLL) project. I've mentioned that, on several experiments, DLL was always significantly faster than some popular deep learning frameworks such as TensorFlow. I'll now go into more details into this comparison and provide all the results. So far, the paper we wrote about these results has not been published, so I'll not provide the paper directly yet.
For those that may not know, DLL is the project I've been developing to support my Ph.D. thesis. This is a neural network framework that supports Fully-Connected Neural Network (FCNN), Convolutional Neural Network (CNN), Restricted Boltzmann Machine (RBM), Deep Belief Network (DBN), Convolutional RBM (CRBM) and Convolutional DBN (CDBN). It also supports a large variety of options such as Dropout, Batch Normalization and Adaptive Learning Rates. You can read read the previous post if you want more information about the new features of the framework. And, as those of you that read my blog frequently may know, I'm a bit obsessed with performance optimization, so I've spent a considerable amount of time optimizing the performance of neural network training, on CPU. Since, at the beginning of my thesis, I had no access to GPU for training, I've focused on CPU. Although there is now support for GPU, the gains are not yet important enough.
Evaluation
To see how fast, or not, the library was, it was compared against five popular machine learning libraries:
Caffe, installed from sources
TensorFlow 1.0, from pip
Keras 2.0, from pip
Torch, installed from sources
DeepLearning4J 0.7, from Maven
I've run four different experiments with all these frameworks and compared the efficiency of each of them for training the same neural networks with the same options. In each case, the training or testing error have also been compared to ensure that each framework is doing roughly the same. I wont present here the details, but in each experiment DLL showed around the same accuracies as the other frameworks. I will only focus on the speed results in this article.
Each experiment is done once with only CPU and once with a GPU. For DLL, I only report the CPU time in both modes, since it's more stable and more optimized.
The code for the evaluation is available online on the Github repository of the frameworks project.
MNIST: Fully Connected Neural Network
The first experiment is performed on The MNIST data set. It consists of 60'000 grayscale images of size 28x28. The goal is to classify each image of a digit from 0 to 9. To solve this task, I trained a very small fully-connected neural network with 500 hidden units in the first layer, 250 in the second and 10 final hidden units (or output units) for classification. The first two layers are using the logistic sigmoid activation function and the last layer is using the softmax activation function. The network is trained for 50 epochs with a categorical cross entropy loss, with mini-batches of 100 images. Here are results of this experiment:
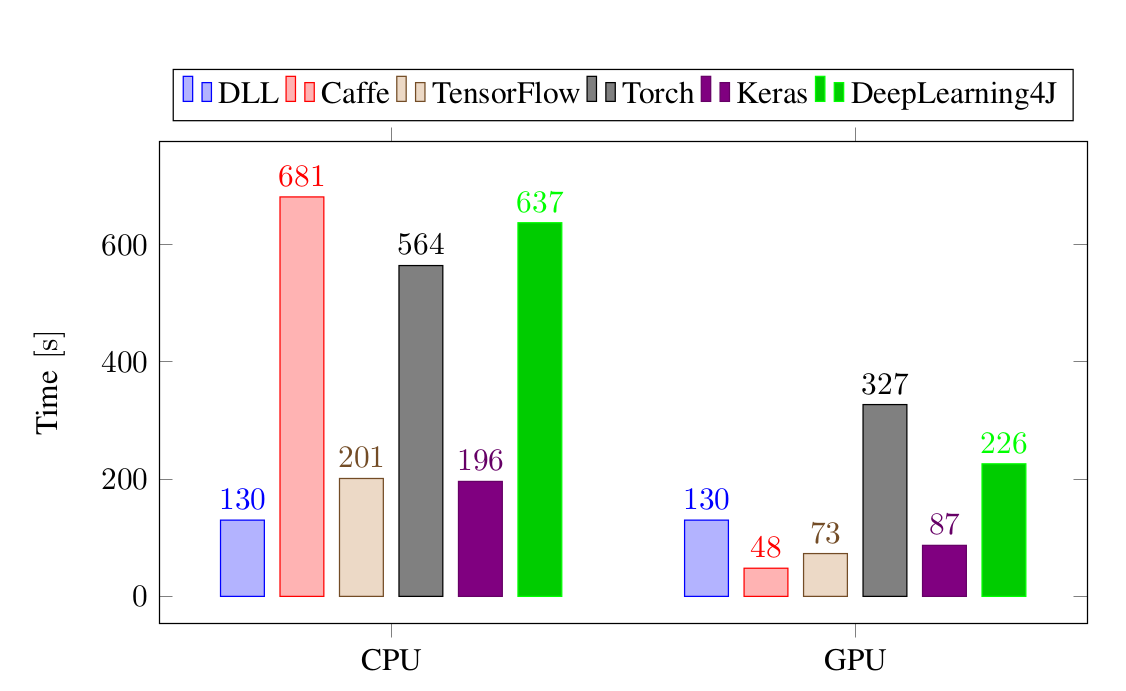
Training time performance for the different frameworks on the Fully-Connected Neural Network experiment, on MNIST. All the times are in seconds.
In DLL mode, the DLL framework is the clear winner here! It's about 35% faster than TensorFlow and Keras which are coming at the second place. DLL is more than four times slower than DLL and the last two frameworks (Caffe and DeepLearning4J) are five times slower than DLL! Once we add a GPU to the system, the results are very different. Caffe is now the fastest framework, three times faster than DLL. DLL is less than two times slower than Keras and TensorFlow. Interestingly, DLL is still faster than Torch and DeepLearning4J.
MNIST: Convolutional Neural Network
Although a Fully-Connected Neural Network is an interesting tool, the trend now is to use Convolutional Neural Network which have proved very efficient at solving a lot of problems. The second experiment is also using the same data set. Again, it's a rather small network. The first layer is a convolutional layer with 8 5x5 kernels, followed by max pooling layer with 2x2 kernel. They are followed by one more convolutional layers with 8 5x5 kernels and a 2x2 max pooling layer. These first four layers are followed by two fully-connected layers, the first with 150 hidden units and the last one with 10 output units. The activation functions are the same as for the first network, as is the training procedure. This takes significantly longer to train than the first network because of the higher complexity of the convolutional layers compared to the fully-connected layers even though they have much less weights. The results are present in the next figure:
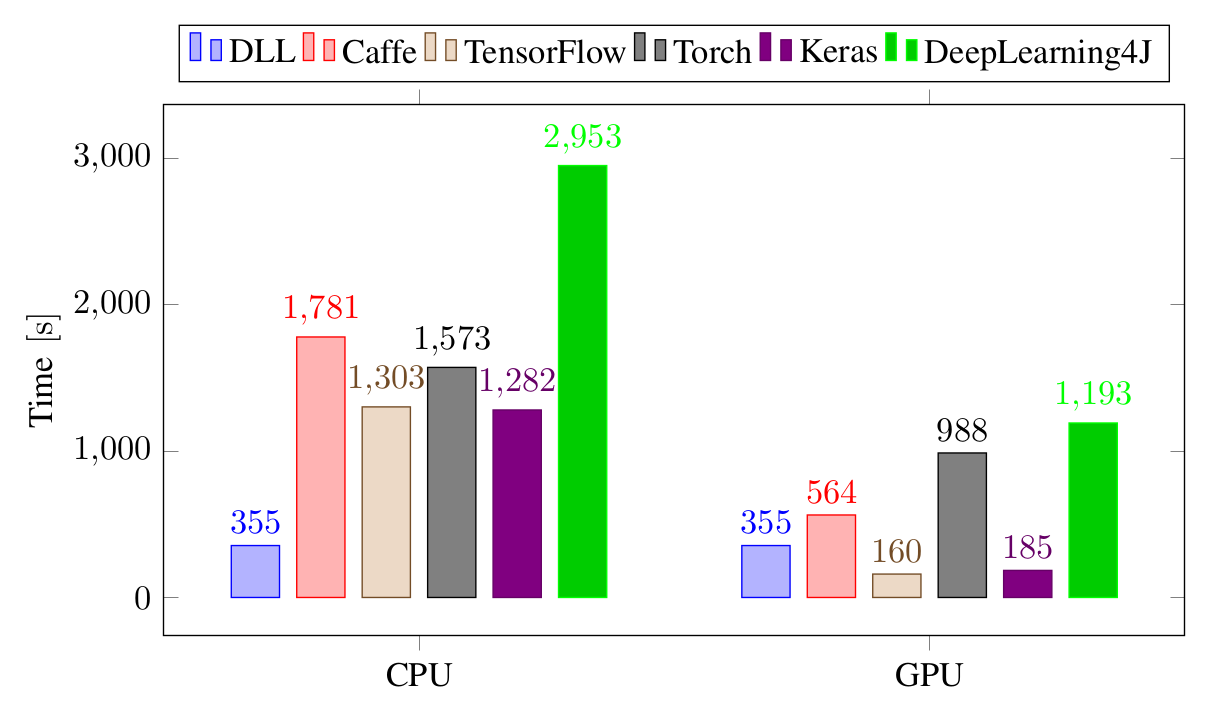
Training time performance for the different frameworks on the Convolutional Neural Network experiment, on MNIST. All the times are in seconds.
Again, on CPU, DLL is the clear winner, by a lot! It's already 3.6 times faster than the second frameworks Keras and TensorFlow, more than four times faster than Caffe and Torch and 8 times faster than DeepLearning4J that is proving very slow on this experiment. Once a GPU is added, Keras and TensorFlow are about twice faster than DLL. However, DLL is still faster than the other frameworks even though they are taking advantage of the GPU.
CIFAR-10
The second data set that is tested is the CIFAR-10 data set. It's an object recognition with 10 classes for classification. The training set is composed of 50'000 colour images for 32x32 pixels. The network that is used for this data set is similar in architecture than the first network, but has more parameters. The first convolutional layer now has 12 5x5 kernels and the second convolutional layer has 24 3x3 kernels. The pooling layers are the same. The first fully-connected has 64 hidden units and the last one has 10 output units. The last layer again use a softmax activation function while the other layers are using Rectifier Linear Units (ReLU). The training is done in the same manner as for the two first networks. Unfortunately, it was not possible to train DeepLearning4J on this data set, even though there is official support for this data set. Since I've had no answer to my question regarding this issue, the results are simply removed from this experiment. It may not seem so but it's considerably longer to train this network because of the larger number of input channels and larger number of convolutional kernels in each layer. Let's get to the results now:
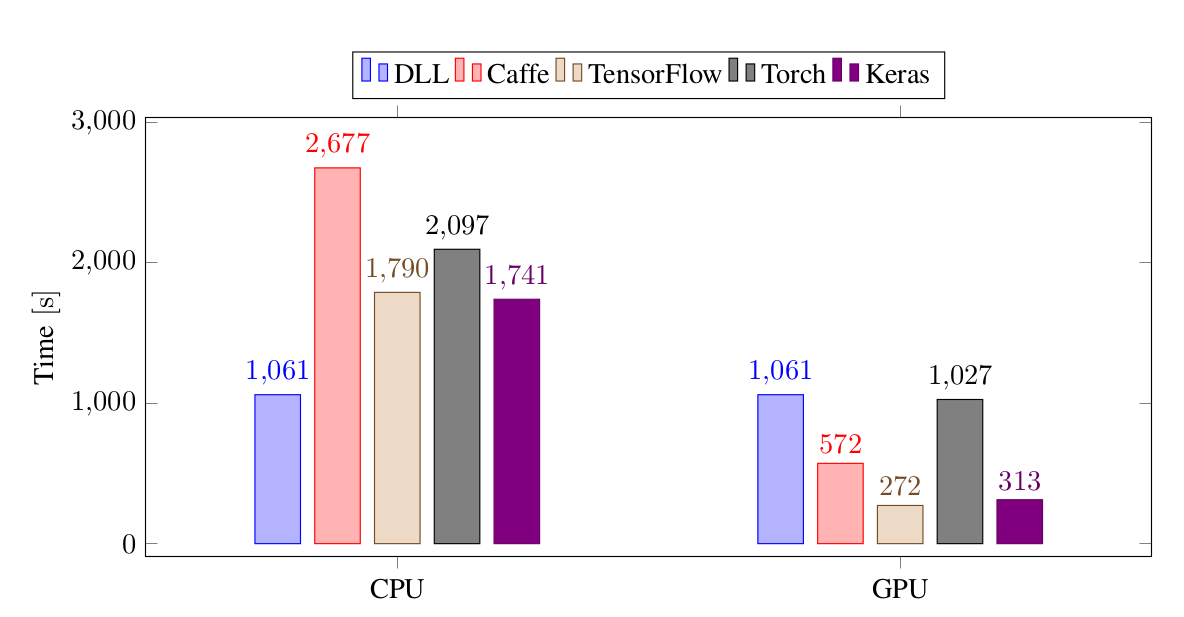
Training time performance for the different frameworks on the Convolutional Neural Network experiment, on CIFAR-10. All the times are in seconds.
DLL is still the fastest on CPU, but the margin is less than before. It's about 40% faster than TensorFlow and Keras, twice faster than Torch and 2.6 times faster than Caffe. Once a GPU is added, DLL is about as fast as Torch but slower than the other three frameworks. TensorFlow and Keras are about four times faster than DLL while Caffe is about twice faster than DLL. We can see that with this larger network, the GPU becomes more interesting and that there is a smaller margin for improvements compared to the other frameworks.
ImageNet
The last experiment is made on the ImageNet data set. I used the ILSVRC 2012 subset, that consists "only" of about 1.2 million images for training. I've resized all the images to 256x256 pixels, this makes for 250 times more colour values than a MNIST image. This dimension and the number of images makes it impractical to keep the dataset in memory. The images must be loaded in batch from the disk. No random cropping or mirroring was performed. The network is much larger to solve this task. The network starts with 5 pairs of convolutional layers and max pooling layers. The convolutional layers have 3x3 kernels, 16 for the first two layers and 32 for the three following one. The five max pooling layers use 2x2 kernels. Each convolutional layer uses zero-padding so that their output features are the same dimensions as the input. They are followed by two fully-connected layer. The first one with 2048 hidden units and the last one with 1000 output units (one for each class). Except for the last layer, using softmax, the layers all uses ReLU. The network is trained with mini-batches of 128 images (except for DeepLearning4J and Torch, which can only use 64 images on the amount of RAM available on my machine). To ease the comparison, I report the time necessary to train one batch of data (or two for DeepLearning4J and Torch). The results, presented in logarithmic scale because of DeepLearning4J disastrous results, are as follows:
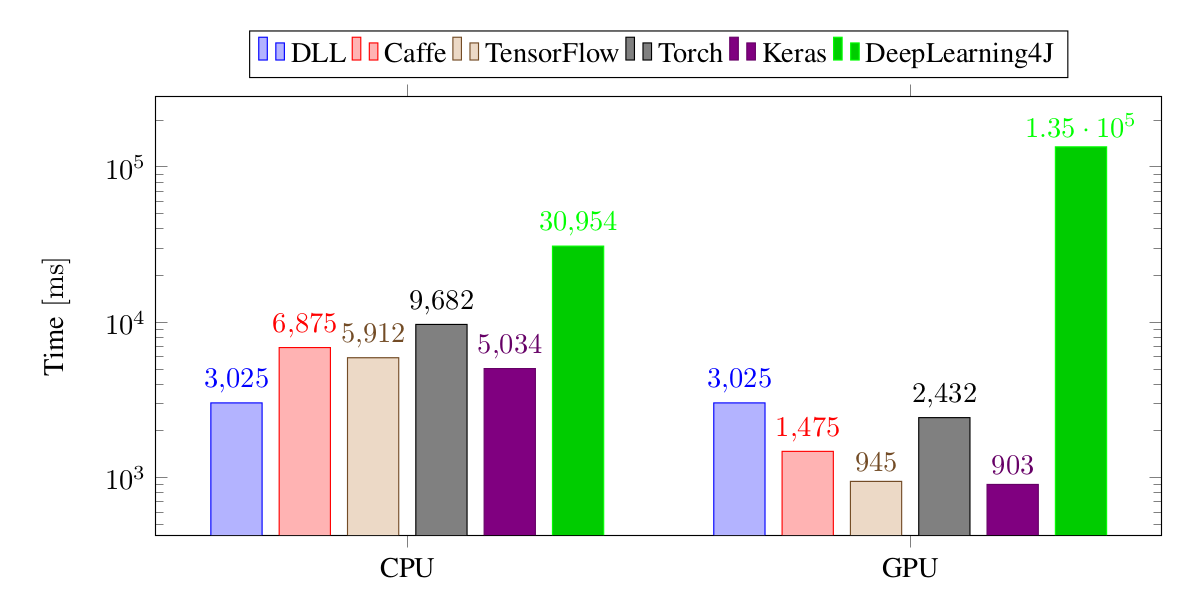
Training time performance for the different frameworks on the Convolutional Neural Network experiment, on ImageNet. The times are the time necessary to train a batch of 128 images. All the times are in milliseconds.
For this final experiment, DLL is again significantly faster than all the other frameworks. It's about 40% faster than Keras, twice faster than TensorFlow and Caffe and more than three times faster than Torch. Although 40% may seem not that much, don't forget that this kind of training may take days, so it can save you a lot of time. All the frameworks are much faster than DeepLearning4J. Based on several posts on the internet, I suspect that this comes from the model of GPU I have been used (GTX 960), but all the other frameworks seem to handle this card pretty well.
Conclusion
I hope this is not too much of a bragging post :P We can see that my efforts to make the code as fast as possible have paid :) As was shown in the experiments, my DLL framework is always the fastest framework when the neural network is trained on CPU. I'm quite pleased with the results since I've done a lot of work to optimize the speed as much as possible and since I'm competing with well-known libraries that have been developed by several persons. Moreover, the accuracies of the trained networks is similar to that of the networks trained with the other frameworks. Even when the other frameworks are using GPU, the library still remains competitive, although never the fastest.
In the next step (I've no idea when I'll have the time though), I will want to focus on GPU speed. This will mostly come from a better support of the GPU in the ETL library on which DLL is based. I have many ideas to improve it a lot, but it will take me a lot of time.
If you want more information on the DLL library, you can have a look at its Github repository and especially at the few examples. You can also have a look at my posts about DLL. Finally, don't hesitate to comment or contact me through Github issues if you have comments or problems with this post, the library or anything ;)
Comments
Comments powered by Disqus