PVS-Studio on C++ Library Review
PVS-Studio is a commercial static analyzer for C, C++ and C#. It works in both Windows and Linux.
It has been a long time since I wanted to test it on my projects. I contacted The PVS-Studio team and they gave me a temporary license so that I can test the tool and make a review.
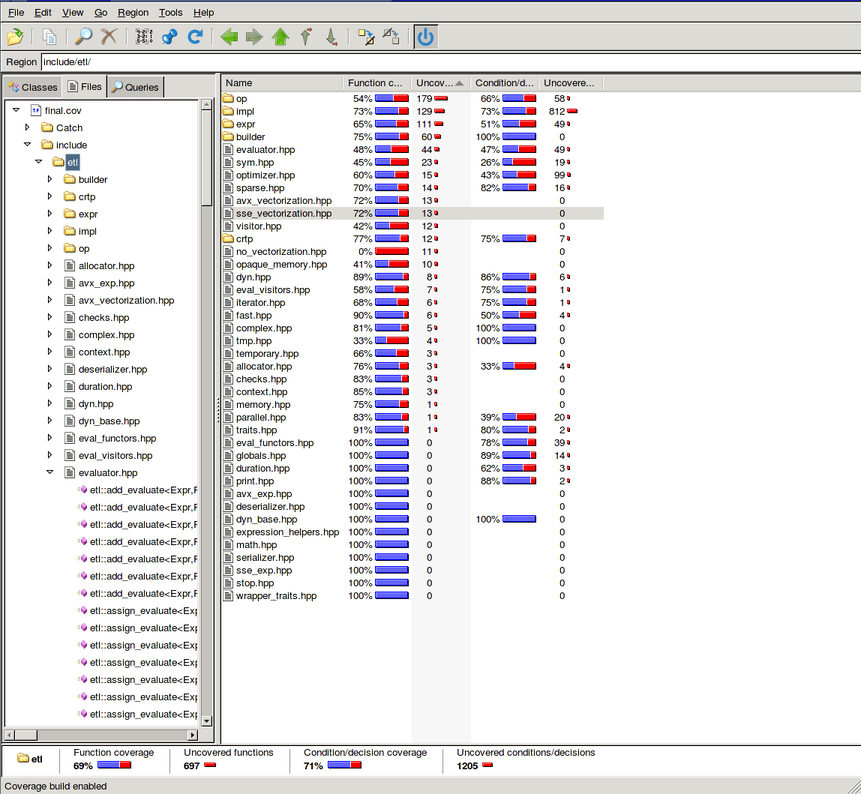
I tried the static analyzer on my Expression Templates Library (ETL) project. This is a heavily-templated C++ library. I tried it on Linux of course.
Usage
The installation is very simple, simply untar an archive and put the executables in your PATH (or use absolute paths). There are also some deb and rpm packages for some distributions. You need strace to make the analyzer work, it should be available on any Linux platform.
The usage of PVS-Studio on Linux should be straightforward. First, you can use the analyzer directly with make and it will detect the invocations of the compiler. For instance, here is the command I used for ETL:
Note that you can use several threads without issues, which is really great. There does not seem to be any slowdown at this stage, probably only collecting compiler arguments.
This first step creates a strace_out file that will be used by the next stage.
Once, the compilation has been analyzed, you can generate the results with the analyze function, for which you'll need a license. Here is what I did:
Unfortunately, this didn't work for me:
Apparently, it's not able to use the strace_out it generated itself...
Another possibility is to use the compilation database from clang to use PVS-Studio. So I generated my compile_commands.json file again (it was not up to date...) with Bear. And then, you only need to run the analyze step:
Make sure you have the same compiler configured than the one used to generate the compilation database to avoid errors with compiler arguments.
Unfortunately, this just printed a load of crap on my console:
(L8Pu(]-'Lo8h>uo(_uv(uo2(->'2h_u(uo2(uvU2K h>'o8a=}Lkk;x[G^%cuaa8acr[VS% $ckUaoc8 c'8>_-o-8>U2cu/kau==-8>c-=cU2]Uf=c U2=u%c&kU__->j}c@uvu2%cJ (L8Pu(]-'Lo8h>uo(_uv(uo2(->'2h_u(uo2(uvU2K h>'o8a=}Lkk;JVJ^%cuaa8acr[VS% $ckUaoc8 c'8>_-o-8>U2cu/kau==-8>c-=cU2]Uf=c U2=u%c&kU__->j}c@uvu2%cJ (L8Pu(]-'Lo8h>uo(_uv(uo2(->'2h_u(uo2(uvU2K h>'o8a=}Lkk;*[G^%cuaa8acr[VS% $ckUaoc8 c'8>_-o-8>U2cu/kau==-8>c-=cU2]Uf=c U2=u%c&kU__->j}c@uvu2%cJ (L8Pu(]-'Lo8h>uo(_uv(uo2(->'2h_u(uo2(uvU2K h>'o8a=}Lkk;b[b^%cuaa8acr[VS% $ckUaoc8 c'8>_-o-8>U2cu/kau==-8>c-=cU2]Uf=c U2=u%c&kU__->j}c@uvu2%cJ (L8Pu(]-'Lo8h>uo(_uv(uo2(->'2h_u(uo2(uvU2K h>'o8a=}Lkk;[[x^%cuaa8acr[VS% $ckUaoc8 c'8>_-o-8>U2cu/kau==-8>c-=cU2]Uf=c U2=u%c&kU__->j}c@uvu2%cJ
Pretty nice, isn't it ?
Let's try again in a file:
The time is quite reasonable for the analysis, it took much less time than the compilation time. In total, it took 88 seconds to analyze all the files. It's much faster than the clang static analyzer.
This time it worked, but the log file is not readable, you need to convert it again:
And finally, you can read the results of the analysis in the errors file.
Results
Overall, PVS-Studio found 236 messages in the ETL library, I was expecting more. I also wish there was an HTML report that include the source code as well as the error message. I had to lookup at the code for each message (you could integrate it in vim and then use the quickfix window to do that). There are some visualization but in things like QtCreator or LibreOffice which I don't have nor want on my computer.
Let's look at the results. For each message, I'll include the message from PVS-Studio and the code if it's relevant.
The first is about using the comma:
include/etl/traits.hpp:674:1: error: V521 Such expressions using the ',' operator are dangerous. Make sure the expression is correct. include/etl/traits.hpp:674:1: error: V685 Consider inspecting the return statement. The expression contains a comma.
template <typename E> constexpr std::size_t dimensions(const E& expr) noexcept { return (void)expr, etl_traits<E>::dimensions(); }
Here I'm simply using the comma operand to ignore expr to avoid a warning. To make this compile in C++11, you need to do it in one line otherwise it's not a constexpr function. It's probably not perfect to use this construct, but there is no problem here.
There is a bunch of these, let's filter them, it remains 207 warnings. Let's jump to the next one:
include/etl/impl/blas/fft.hpp:29:1: error: V501 There are identical sub-expressions to the left and to the right of the '==' operator: (DFTI_SINGLE) == DFTI_SINGLE
inline void fft_kernel(const std::complex<float>* in, std::size_t s, std::complex<float>* out) { DFTI_DESCRIPTOR_HANDLE descriptor; void* in_ptr = const_cast<void*>(static_cast<const void*>(in)); DftiCreateDescriptor(&descriptor, DFTI_SINGLE, DFTI_COMPLEX, 1, s); //Specify size and precision DftiSetValue(descriptor, DFTI_PLACEMENT, DFTI_NOT_INPLACE); //Out of place FFT DftiCommitDescriptor(descriptor); //Finalize the descriptor DftiComputeForward(descriptor, in_ptr, out); //Compute the Forward FFT DftiFreeDescriptor(&descriptor); //Free the descriptor }
Unfortunately, the error is inside the MKL library. Here, I really don't think it's an issue. There is pack of them. I forgot to exclude non-ETL code from the results. Once filter from all dependencies, 137 messages remain.
include/etl/eval_functors.hpp:157:1: warning: V560 A part of conditional expression is always false: !padding.
This is true, but not an issue since padding is a configuration constant that enables the use of padding in vector and matrices. There was 27 of these at different locations and with different configuration variables.
include/etl/op/sub_view.hpp:161:1: note: V688 The 'i' function argument possesses the same name as one of the class members, which can result in a confusion.
This is again true, but not a bug in this particular case. It is still helpful and I ended up changing these to avoid confusion. Again, there was a few of these.
etl/test/src/conv_multi_multi.cpp:23:1: error: V573 Uninitialized variable 'k' was used. The variable was used to initialize itself.
This one is in the test code:
for (size_t k = 0; k < etl::dim<0>(K); ++k) { for (size_t i = 0; i < etl::dim<0>(I); ++i) { C_ref(k)(i) = conv_2d_valid(I(i), K(k)); // HERE } }
I don't see any error, k is initialized correctly to zero in the first loop. This is a false positive for me. There were several of these in different places. It seems to that the use of the operator() is confusing for PVS-Studio.
include/etl/traits.hpp:703:1: note: V659 Declarations of functions with 'rows' name differ in the 'const' keyword only, but the bodies of these functions have different composition. This is suspicious and can possibly be an error. Check lines: 693, 703.
template <typename E, cpp_disable_if(decay_traits<E>::is_fast)> std::size_t rows(const E& expr) { //693 return etl_traits<E>::dim(expr, 0); } template <typename E, cpp_enable_if(decay_traits<E>::is_fast)> constexpr std::size_t rows(const E& expr) noexcept { //703 return (void)expr, etl_traits<E>::template dim<0>(); }
Unfortunately, this is again a false positive because PVS-Studio failed to recognized SFINAE and therefore the warning is wrong.
include/etl/builder/expression_builder.hpp:345:1: note: V524 It is odd that the body of '>>=' function is fully equivalent to the body of '*=' function.
This one is interesting indeed. It is true that they are exactly because in ETL >> is used for scalar element-wise multiplication. This is quite interesting that PVS-Studio points that out. There was a few of these oddities but all were normal in the library.
etl/test/src/compare.cpp:23:1: error: V501 There are identical sub-expressions to the left and to the right of the '!=' operator: a != a
Again, it is nice that PVS-Studio finds that, but this is done on purpose on the tests to compare an object to itself. If I remove all the oddities in the test cases, there are only 17 left in the headers. None of the warnings on the test case was serious, but there was no more false positives either, so that's great.
template <typename L, cpp_disable_if((vec_enabled && all_vectorizable<vector_mode, L>::value))> value_t<L> sum(const L& lhs, size_t first, size_t last) { cpp_unused(lhs); cpp_unused(first); cpp_unused(last); cpp_unreachable("vec::sum called with invalid parameters"); }
This one is interesting. It's not a false positive since indeed the function does not return a value, but there is a __builtin_unreachable() inside the function and it cannot be called. In my opinion, the static analyzer should be able to handle that, but this is really a corner case.
include/etl/sparse.hpp:148:1: note: V550 An odd precise comparison: a == 0.0. It's probably better to use a comparison with defined precision: fabs(A - B) < Epsilon.
This is not false, but again this is intended because of the comparison to zero for a sparse matrix. There were 10 of these in the same class.
include/etl/impl/blas/fft.hpp:562:1: note: V656 Variables 'a_padded', 'b_padded' are initialized through the call to the same function. It's probably an error or un-optimized code. Consider inspecting the 'etl::size(c)' expression. Check lines: 561, 562.
dyn_vector<etl::complex<type>> a_padded(etl::size(c)); dyn_vector<etl::complex<type>> b_padded(etl::size(c));
It's indeed constructed with the same size, but for me I don't think it's an odd pattern. I would not consider that as a warning, especially since it's a constructor and not a assignment.
include/etl/dyn_base.hpp:312:1: warning: V690 The 'dense_dyn_base' class implements a copy constructor, but lacks the '=' operator. It is dangerous to use such a class.
This is again a kind of corner case in the library because it's a base class and the assignment is different between the sub classes and not a real assignment in the C++ sense.
include/etl/impl/reduc/conv_multi.hpp:657:1: warning: V711 It is dangerous to create a local variable within a loop with a same name as a variable controlling this loop.
for (std::size_t c = 0; c < C; ++c) { for (std::size_t k = 0; k < K; ++k) { conv(k)(c) = conv_temp(c)(k); } }
This is again a false positive... It really seems that PVS-Studio is not able to handle the operator().
include/etl/impl/pooling.hpp:396:1: error: V501 There are identical sub-expressions to the left and to the right of the '||' operator: P1 || P2 || P1
template <size_t C1, size_t C2, size_t C3,size_t S1, size_t S2, size_t S3, size_t P1, size_t P2, size_t P3, typename A, typename M> static void apply(const A& sub, M&& m) { const size_t o1 = (etl::dim<0>(sub) - C1 + 2 * P1) / S1 + 1; const size_t o2 = (etl::dim<1>(sub) - C2 + 2 * P2) / S2 + 1; const size_t o3 = (etl::dim<2>(sub) - C3 + 2 * P3) / S3 + 1; if(P1 || P2 || P1){
Last but not least, this time, it's entirely true and it's in fact a bug in my code! The condition should be written like this:
This is now fixed in the master of ETL.
Conclusion
The installation was pretty easy, but the usage was not as easy as it could because the first method by analyzing the build system did not work. Fortunately, the system supports using the Clang compilation database directly and therefore it was possible to use.
Overall, it found 236 warnings on my code base (heavily templated library). Around 50 of them were in some of the extend libraries, but I forgot to filter them out. The quality of the results is pretty good in my opinion. It was able to find a bug in my implementation of pooling with padding. Unfortunately, there was quite a few false positives, due to SFINAE, bad handling of the operator() and no handling of __builtin_unreachable. The remaining were all correct, but were not bug considering their usages.
To conclude, I think it's a great static analyzer that is really fast compared to other one in the market. There are a few false positives, but it's really not bad compared to other tools and some of the messages are really great. An HTML report including the source code would be great as well.
If you want more information, you can consult the official site. There is even a way to use it on open-source code for free, but you have to add comments on top of each of your files.
I hope it was helpful ;)